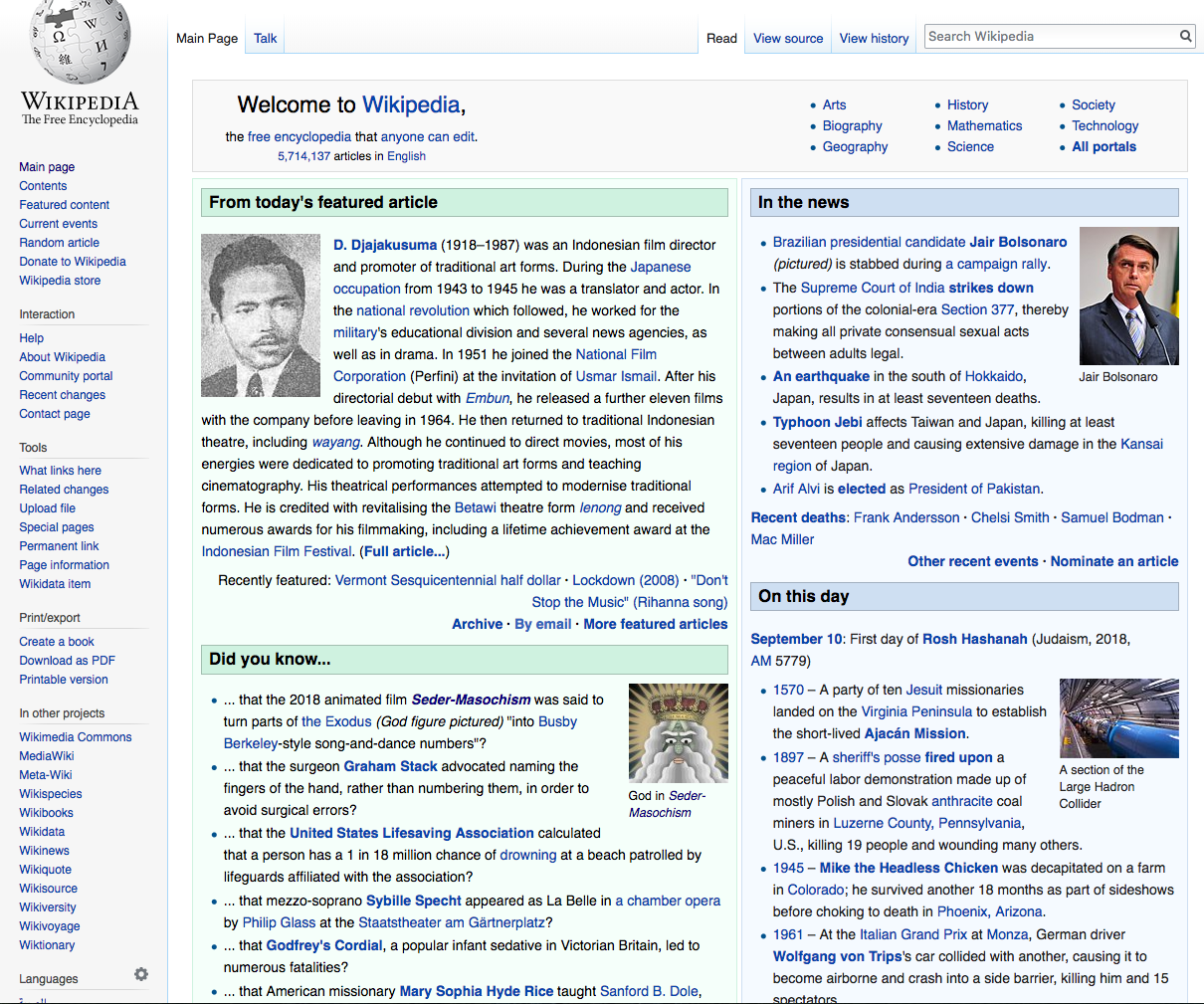
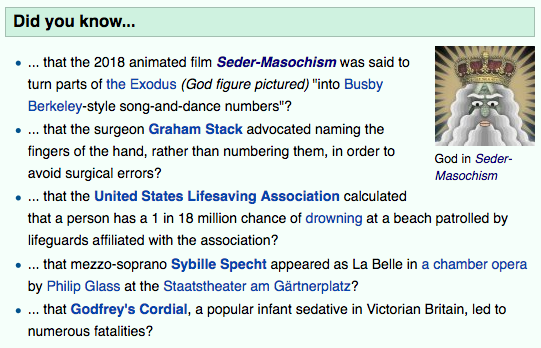
Today (September 10 2018) it was on Wikipedia’s main page, so I got screenshots for posterity. The article itself is here. As of my last reading it had not yet been defaced by misogynists! But sooner or later it will be.

Animator. Director. Artist. Scapegoat.

Dear Internet,
You know what should be really easy to find online? Good quality, Public Domain vintage illustrations. You know, things like this:

I found this on Flickr, where someone claims full copyright on it. That’s copyfraud, but understandable because Flickr’s default license is full copyright (all the more reason to ignore copyright notices!). But copyfraud is not the main problem. The main problem is that images like this are painfully difficult to find online, especially at high resolutions (and this image is only available at medium resolution – up to 604 pixels high, which is barely usable for most purposes but higher than much of what you find online).
The images are out there – and with zillions of antique books being scanned, their vintage illustrations are being scanned right along with them. But the images are buried in the text, and often the scan quality is poor. Images should be scanned at high quality, and tagged for searchability.
Take the American Memory archive of the Library of Congress. Lots and lots of historical documents here, but no way for me to find an image of, say, a horse.
Most book–scanning projects focus on texts, not illustrations. Many interesting and useful illustrations are buried within these scans, uncatalogued and inaccessible. Scan quality is set for text, not illustrations, so even if one can find a choice illustration buried within, its quality is usually too low to use.
Archive.org is great (I love you, archive.org!) but does not have an image archive. Still images are not among their “Media Types” (which consist of Moving Images, Texts, Audio, Software, and Education). So I went spelunking through their texts, starting with “American Libraries,” and searched for something easy: “horse.” Surely I could find a nice usable etching of a horse in there somewhere. I eventually found “The Harness Horse” by Sir Walter Gilbey, from 1898.

Nice illustrations! Can I use them? Unfortunately, no. The book is downloadable as PDF and various e-publication formats, but when I try to extract the illustrations, I get a mess:



Clearly something is messed up here. Was it just that page? Alas, no:

The scans have some flaws that PDFs and Photoshop can’t cope with:

These images are not useable, which is a pity because they are very nice illustrations. And they seem to be among the higher quality scans, which again isn’t saying much.
Let me add that it’s great these books are being scanned at all! That’s definitely better than losing them entirely. But as an artist, it saddens me that we’re neglecting this wealth of visual art. I’d like to see our rich visual history properly archived. Our bias favoring text over pictures is especially ironic considering how much more efficiently information is communicated to humans through images; “A picture is worth a thousand words,” or more. That’s why I’m a cartoonist, after all.
I was able to extract one clean image from the book, on page 48:

Unfortunately I can’t use this illustration for my purposes, but maybe someone else can. I’ve already gone through the trouble of finding it in a text, extracting it, and rotating it. If only there were some image archive I could upload it to at high resolution, so someone else could use it. I could tag it, to make it easier to find. I could include all kinds of useful metadata, like what book it was from and when it was published; but even if that was too bothersome, I could at least include tags like “horse,” “rider” and “engraving.” Wouldn’t it be nice if such an archive existed? Wikimedia Commons is close, although I dread uploading things there after having all my open-licensed comics deleted by an overzealous editor. But maybe they’re our best hope.
Continuing my searches on archive.org, I found this ostensibly Public Domain, vintage horse book with line illustrations. Unfortunately this is controlled by Google Books. It’s “free” to read online in Google’s reader, which doesn’t allow any image export. It also doesn’t allow me to zoom in.

All those illustrations, trapped at low resolution, unusable (even if they were tagged/catalogued, which they aren’t). This is our “Public Domain.” Who exactly is benefitting from having these 18th Century illustrations inaccessible to today’s artists?
Then there’s Dover Books. I loved Dover books growing up – they introduced me to the idea of the Public Domain. Dover reproduces vintage illustrations in books for artists and designers. Their paper books were reasonably priced, and you could use the illustrations for anything, without restriction. Browsing was free, so I would flip through the pages in the book store, and if it had what I needed, I’d buy it.
Dover is still selling books, but the prices are now relatively high, few are carried in bookstores, and they prohibit browsing online. You have to shell out $15 to find out if what you need is in the book, and how could you know? They seem to be clinging to an outdated copyright model, and rather than selling things of added value, they are simply blocking access to existing Public Domain works, in order to collect a toll.
What else has kept a good public archive of Public Domain images from existing? Some artists and archivists do make high quality scans of vintage illustrations – and keep them to themselves. I guess we could call this “image hoarding.” I assume the reasoning is, “I went through all the trouble to scan it, why should I share? Others can pay me if they want a copy.” Also there’s the “finders, keepers” reasoning: “anyone else is free to find the same illustration in another antique book, but I found this one, so it’s mine.” And so these images remain inaccessible, not part of any public archive.
Wikimedia Commons is the best public image archive I know of right now. A bit of searching led me to their “Engravings of Horses” category, which yielded some nice images. Unfortunately, many of these are not available at sufficiently high resolutions.
The maximum size of this image is 800 × 608 pixels, which limits its use. Limited image sizes and limited selection have been the biggest obstacles to my relying more on Wikimedia Commons; but it can get better. Maybe it will. It would be nice if something became the public vintage image archive I and so many other artists need.
Note: Please, please continue uploading my comics to WikiMedia Commons, beloved uploaders! Nina’s Adventures is next. I completely endorse and support this work! Thank you! I love you! I post the rant below because, well, it’s on my mind now, and life isn’t perfect.
Continue reading “My Wikimedia Rant”
We need Sita subtitled in as many languages as possible!
Attention subtitlers:
If your subtitle files are ready before the upcoming DVD is mastered, we will include them on the upcoming “official” DVD. The DVD will be authored the week of March 23, 2009. Thanks!

Big ol’ hi-res “Sita” PNGs now at archive.org! They’re suitable for print publication.
More coming, as I get time to deal with everything. Whenever that is.
Speaking of which, does anyone want to help make the “Frequently Asked Interview Questions” part of the Sita FAQ? This would involve going through all the interviews I’ve done about Sita Sings the Blues (a few are linked to here, the rest need to be googled), determining which questions are asked over and over again, and consolidating the answers based on what I’ve already said. If I tackle it now that’ll mean another day I don’t get to the new DVD packaging and other tasks I have to do myself. We’ve got a wiki; I’m still learning how to use it, but feel free to start a FAQ there with a brand new FAQ section. Thanks!